IGBT 温度预测 二 随机森林
昨天介绍了一份关于IGBT温度的测试数据集 ABB_competition,并查看了数据的内容及特性。
今天继续做数据探究和预测。
数据清理
昨天我们查看了各变量的箱线图,发现有些变量的尾巴较长,这里我们认为他们是异常值,试图删除这些值。
首先,我们需要计算每个特征的四分位距(IQR),以确定异常值的范围。然后,我们可以使用这些范围来识别和删除异常值。这里使用了1.5倍IQR的标准来定义异常值的范围。
# 计算每个特征的四分位距(IQR)
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
# 定义异常值范围
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 识别异常值
outliers = (df < lower_bound) | (df > upper_bound)
# 统计异常值个数
num_outliers = outliers.sum()
print(f"特征异常值个数: {num_outliers}")
# 删除异常值
outliers = outliers.any(axis=1)
cleaned_df = df[~outliers]
# 打印结果
print(f"原始数据行数: {len(df)}")
print(f"删除异常值后的数据行数: {len(cleaned_df)}")
结果如下:
特征异常值个数: time 0
ambient_temp 37
dc_bus_volt 2634
motor_current 0
motor_power 186
motor_speed 0
motor_torque 5
igbt_junction_temp 143
dtype: int64
原始数据行数: 13471
删除异常值后的数据行数: 10509
根据异常值检测和删除的结果:
-
异常值个数: 在数据集中,各特征的异常值数量不同。其中,dc_bus_volt 特征异常值最多,达到了 2634 个,而 ambient_temp 和 motor_power 也分别有 37 和 186 个异常值。
-
数据行数变化: 在删除异常值后,数据集的行数从原始的 13471 行减少到了 10509 行。通过四分位距(IQR)方法识别并删除异常值,清理了一部分不符合正常分布的数据点,使数据更加健壮。
查看删除异常值后的箱线图
# 创建子图
fig = make_subplots(rows=4, cols=2, subplot_titles=df.columns[1:])
# 添加箱线图到子图
for i, col in enumerate(cleaned_df.columns[1:]):
row_num = i // 2 + 1
col_num = i % 2 + 1
# 绘制箱线图
box_trace = px.box(cleaned_df, y=col, title=f"{col}")
fig.add_trace(box_trace["data"][0], row=row_num, col=col_num)
# 更新布局
fig.update_layout(height=row_num * 300, width=800, title_text="箱线图 - 米克网")
# 显示图表
fig.show()

这里可以看到除dc_bus_volt外,其他变量已无大的异常值。我们可以按照上面的方法继续对数据进行清理,但是可能删除的数据过多。先保留目前的结果。
下面我们将开始使用高级树模型和深度学习模型两种方法进行数据预测。
今天先探究使用高级树模型的方法。
数据划分
开始之前,我们对数据进行预处理,定义目标特征,划分训练数据和测试数据。这里为了不让模型对验证集的数据进行训练,另外方便后期查看温度随时间变化的情况,采用按顺序分割数据集的方式。
import pandas as pd
# 将时间戳字段转换为数字格式
cleaned_df["time"] = pd.to_datetime(cleaned_df["time"])
# 定义特征和目标变量
features = cleaned_df[
[
"ambient_temp",
"dc_bus_volt",
"motor_current",
"motor_power",
"motor_speed",
"motor_torque",
]
]
target = cleaned_df["igbt_junction_temp"]
# 按顺序划分数据集
# 80% 用于训练集,10% 用于验证集,10% 用于测试集
num_samples = len(features)
train_size = int(0.8 * num_samples)
val_size = int(0.1 * num_samples)
# 训练集、验证集和测试集划分时保留时间戳
X_train, y_train, time_train = (
features[:train_size],
target[:train_size],
df["time"][:train_size],
)
X_val, y_val, time_val = (
features[train_size : train_size + val_size],
target[train_size : train_size + val_size],
df["time"][train_size : train_size + val_size],
)
X_test, y_test, time_test = (
features[train_size + val_size :],
target[train_size + val_size :],
df["time"][train_size + val_size :],
)
# 输出各个集合的大小
print(f"训练集大小: {len(X_train)}")
print(f"验证集大小: {len(X_val)}")
print(f"测试集大小: {len(X_test)}")
训练集大小: 8407
验证集大小: 1050
测试集大小: 1052
随机森林模型
from sklearn.ensemble import RandomForestRegressor
# 创建高级树模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 获取特征重要性
feature_importance = rf_model.feature_importances_
# 获取特征名称
feature_names = X_train.columns
print(feature_names, feature_importance)
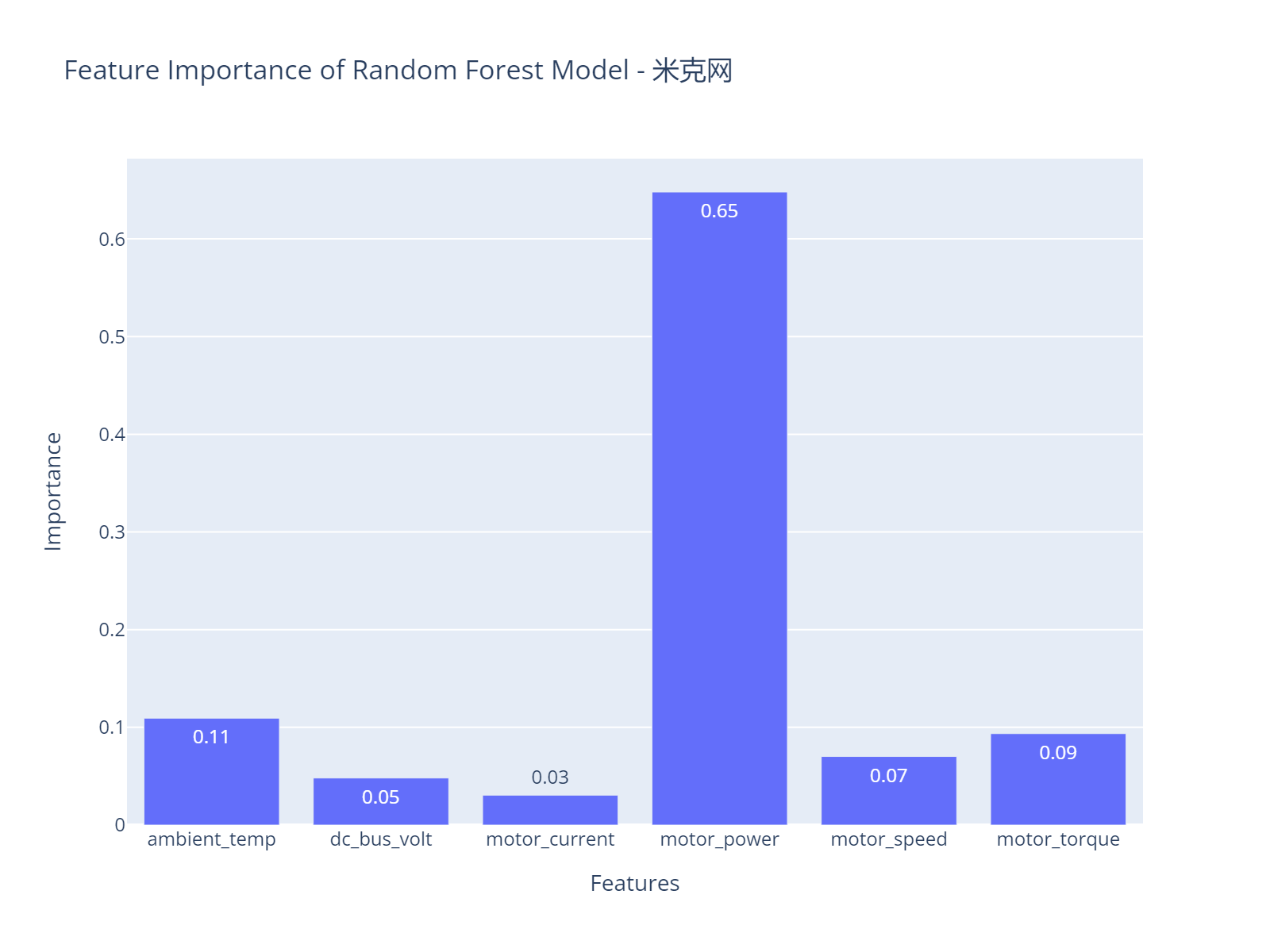
每个特征的重要性值表示模型在进行预测时认为该特征对于解释目标变量(在这里是温度)的贡献程度。重要性值越高,表示模型认为该特征在预测中具有更大的影响力。
在本例中
-
'motor_power' 的重要性最高,为 0.6480096。这表明模型认为电机功率对于目标变量的解释贡献最大。
-
其他特征的重要性分别为 'ambient_temp'(0.109414)、'dc_bus_volt'(0.04815782)、'motor_current'(0.03060807)、'motor_speed'(0.07020228)、'motor_torque'(0.09360824)。这些值表示相对于 'motor_power',这些特征对于模型的解释贡献较小。
预测结果与测试结果对比
下面我们查看验证数据集的预测结果和测试结果对比。
首先,对测试集进行预测,并创建一个散点图来可视化预测值和实际值的关系。
from sklearn.metrics import mean_squared_error
# 使用模型预测验证集
y_val_pred = rf_model.predict(X_val)
# 计算均方根误差(RMSE)
rmse_val = mean_squared_error(y_val, y_val_pred, squared=False)
print(f"验证集均方根误差 (RMSE): {rmse_val}")
# 使用plotly绘图
fig = go.Figure()
# 添加实际值和预测值的散点图
fig.add_trace(go.Scatter(x=time_val, y=y_val, mode="lines+markers", name="实际值"))
fig.add_trace(go.Scatter(x=time_val, y=y_val_pred, mode="lines+markers", name="预测值"))
# 设置图形布局
fig.update_layout(
title="验证集 igbt_junction_temp 随时间的变化趋势图 - 预测 vs 实际",
width=800,
height=600,
showlegend=True,
)
# 显示图形
fig.show()
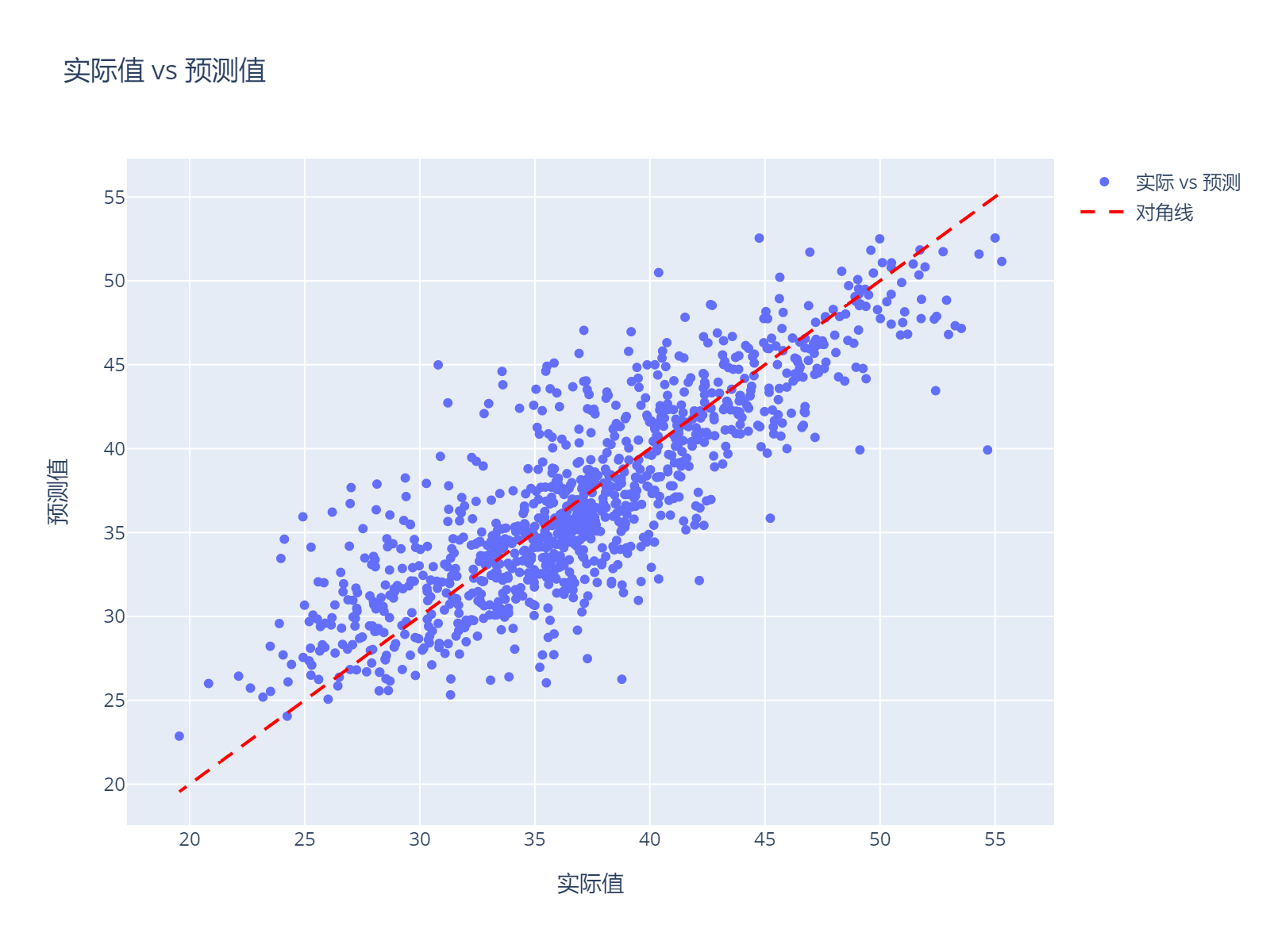
x轴是实际值y_test,y轴是预测值rf_predictions。在图形中添加了一条对角线,这条线的x和y值都是实际值y_test。这条线的目的是为了更好地对比预测值和实际值。
验证集均方根误差 (RMSE): 3.4553
另外,以时间为x轴查看对比预测值和实际值,这样可能更直观。
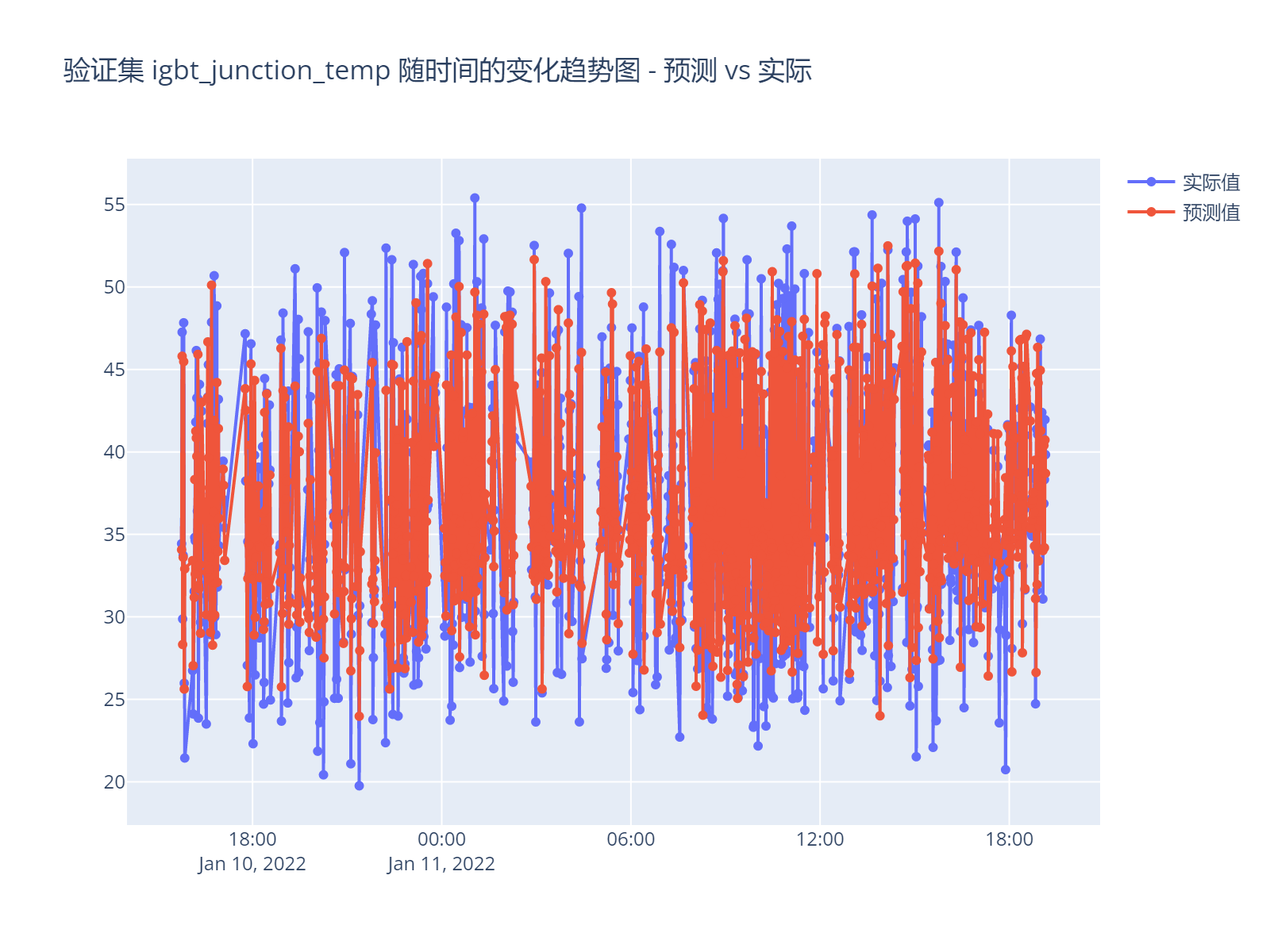
放大图形看一段时间的结果
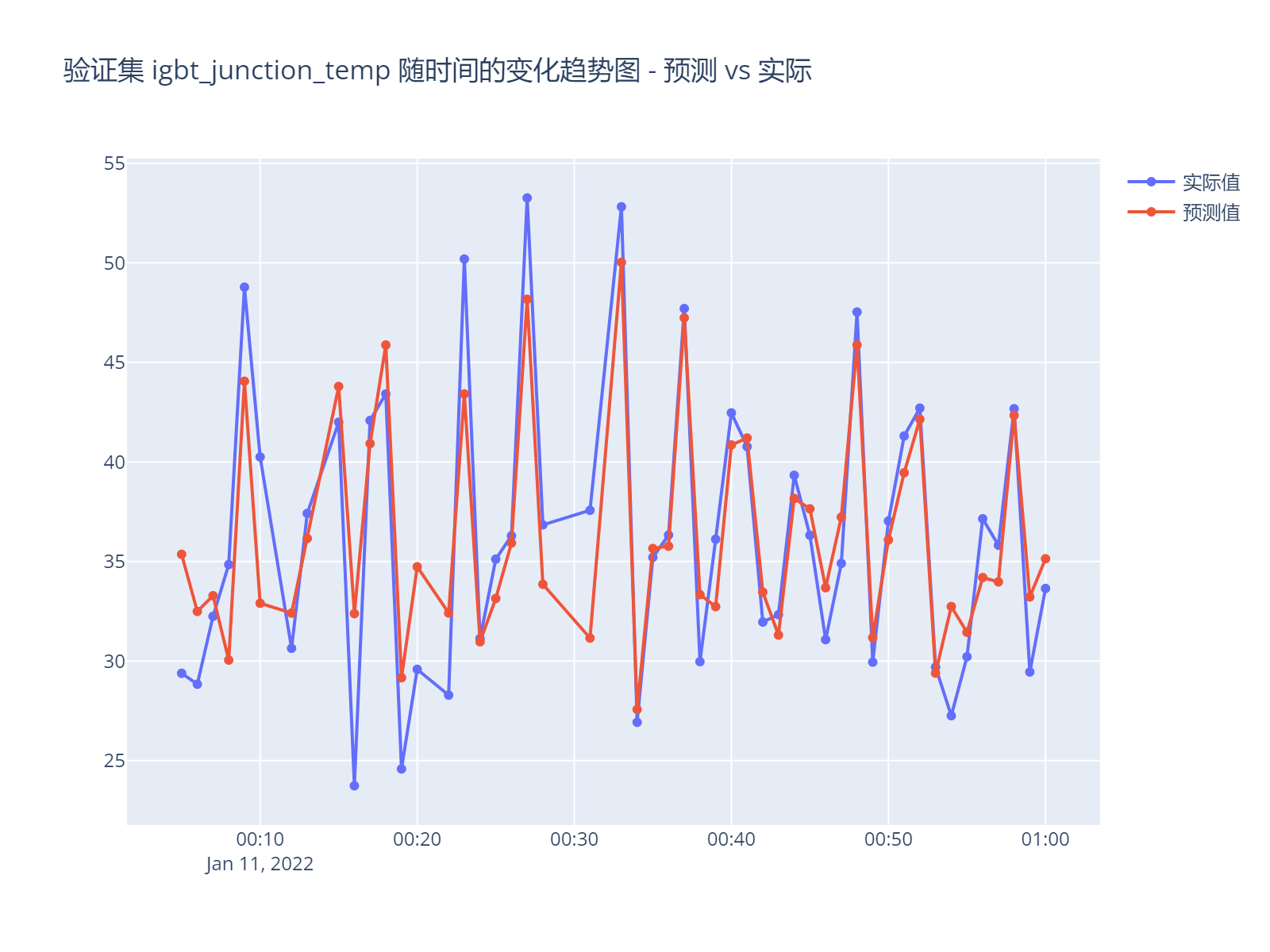
大体上看预测数据能够在温度上升下降的趋势上进行准确预测,但数值还是有些差别,大概3~5C,预测结果不如测试结果变化剧烈。
明天有时间继续探究使用深度学习模型的方式进行预测。