IGBT 温度预测 一 了解数据
昨天那份关于IGBT加速老化测试的数据可能需要对半导体失效机理和模式有较深的背景知识才能进一步分析。所以今天找一份其它的数据来练手。
这份数据标题为 ABB_competition,上传者 LeeLeon_MS。
下面我将使用python来处理这份数据,今天作为第一期,查看数据并作初步的EDA分析。数据分析过程参考LeeLeon_MS。
EDA的一般方法流程
当进行探索性数据分析(EDA)时,可以采取以下分析提纲来了解数据集的特征和结构。在读入 Excel 文件后,请提供表头文件内容,以便我可以根据具体的数据列展开分析。
-
数据概览
- 查看前几行数据,了解数据的整体结构。
- 确保数据读取正确,检查缺失值情况。
-
基本统计信息
-
计算各个数值型列的基本统计信息,如均值、中位数、标准差等。
- 考虑描述性统计信息对数据分布有何启示。
-
数据类型
-
检查每个列的数据类型,确保它们符合预期。
- 根据需要,可能需要进行数据类型的转换。
-
缺失值处理
-
分析缺失值的分布情况,确定缺失值的处理策略。
- 考虑填充缺失值、删除包含缺失值的行或列等方式。
-
数据分布可视化
-
绘制直方图、箱线图等图表,了解数值型数据的分布情况。
- 对分类型数据,考虑使用条形图来展示各类别的分布情况。
-
相关性分析
-
计算各个特征之间的相关系数,以了解它们之间的关系。
- 使用热力图可视化相关性矩阵。
-
异常值检测
-
寻找可能存在的异常值,使用散点图等方式进行可视化。
- 考虑使用统计方法或领域知识来处理异常值。
-
特征工程
-
根据数据分析的结果,考虑是否需要进行特征工程,如创建新特征、进行变换等。
-
类别特征分析
-
对于分类型特征,可以使用条形图或饼图来展示各个类别的分布情况。
- 分析类别特征与目标变量之间的关系。
-
时间序列分析
-
如果数据包含时间序列信息,进行时间序列的探索性分析。
- 查看趋势、季节性等特征。
-
目标变量分析
-
对目标变量进行深入分析,了解其分布情况和影响因素。
-
数据集的其他特殊性质
-
根据具体问题,可能需要进一步分析数据集中特殊的特征或关系。
读入数据
import pandas as pd
# 用你实际的文件路径替换下面的'your_file_path.xlsx'
file_path = 'data1_final(absolution)_1.xlsx'
# 读取Excel文件
df = pd.read_excel(file_path)
# 显示前几行数据,确认读取正确
print(df.head())
# 计算起始时间差
start_time = df['time'].min()
end_time = df['time'].max()
time_difference = end_time - start_time
print(f"起始时间:{start_time}")
print(f"结束时间:{end_time}")
print(f"数据时间差:{time_difference}")
# 计算数据条数
data_count = len(df)
print(f"数据条数:{data_count}")
# 统计每列的缺失值数量
missing_values = df.isnull().sum()
# 打印每列的缺失值数量
print("每列缺失值数量:")
print(missing_values)
输出结果如下:
time ambient_temp dc_bus_volt motor_current motor_power \
0 2022-01-01 00:08:00 22.3 524.68 173.97 17.291765
1 2022-01-01 00:09:00 22.5 658.61 0.00 22.118750
2 2022-01-01 00:10:00 22.7 508.96 273.53 53.614706
3 2022-01-01 00:11:00 23.1 535.47 0.00 18.922000
4 2022-01-01 00:13:00 23.6 535.30 78.03 34.322353
motor_speed motor_torque igbt_junction_temp
0 391.189412 46.58125 26.235294
1 300.628333 45.81250 31.620000
2 475.775500 79.23125 44.505000
3 371.711111 34.54000 24.675000
4 392.930000 68.50000 37.290000
起始时间:2022-01-01 00:08:00
结束时间:2022-01-15 19:19:00
数据时间差:14 days 19:11:00
数据条数:13471
每列缺失值数量:
time 0
ambient_temp 0
dc_bus_volt 0
motor_current 0
motor_power 0
motor_speed 0
motor_torque 0
igbt_junction_temp 0
dtype: int64
这个数据集有13471行和8列,这8个变量分别是:
- 时间(time)
- 环境温度(ambient_temp)
- 直流电压(dc_bus_volt)
- 电机电流(motor_current)
- 电机功率(motor_power)
- 电机速度(motor_speed)
- 电机扭矩(motor_torque)
- IGBT结温(igbt_junction_temp),目标变量,后面将根据其他变量预测IGBT的结温
数据集中各列没有缺失的数据。
数据是从2022-01-01 00:08:00 到 2022-01-15 19:19:00,总共14 天 19:11:00。
查看数据统计信息
statistics = df.describe()
statistics
结果如下
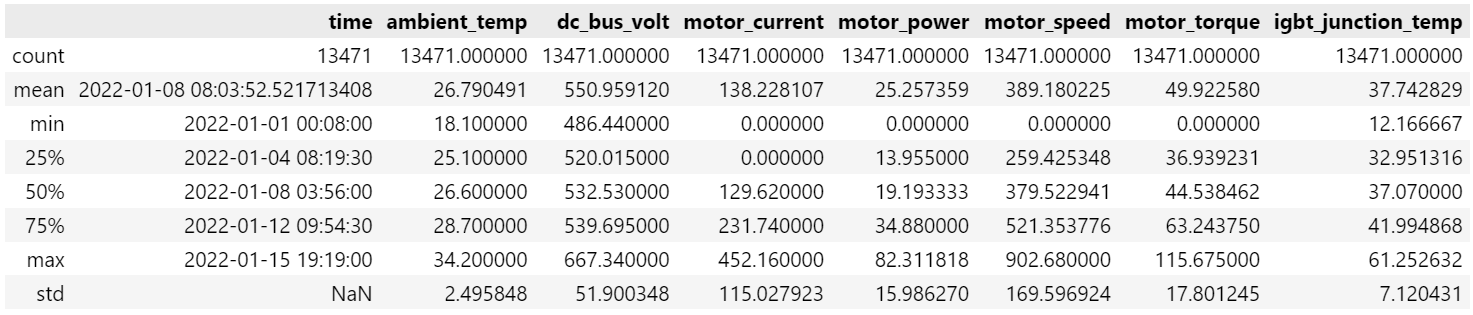
上面统计出了各变量的均值,最大最小值,均方差,中位数,四分位数。
查看各变量随时间的变化情况
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# 创建子图
fig = make_subplots(rows=4, cols=2, subplot_titles=df.columns[1:], shared_xaxes=True)
# 添加折线图到子图
for i, col in enumerate(df.columns[1:]):
row_num = i // 2 + 1
col_num = i % 2 + 1
fig.add_trace(
go.Scatter(x=df["time"], y=df[col], mode="lines", name=col),
row=row_num,
col=col_num,
)
# 更新布局
fig.update_layout(height=1000, width=800, title_text="时序图 - 米克网")
# 显示图表
fig.show()
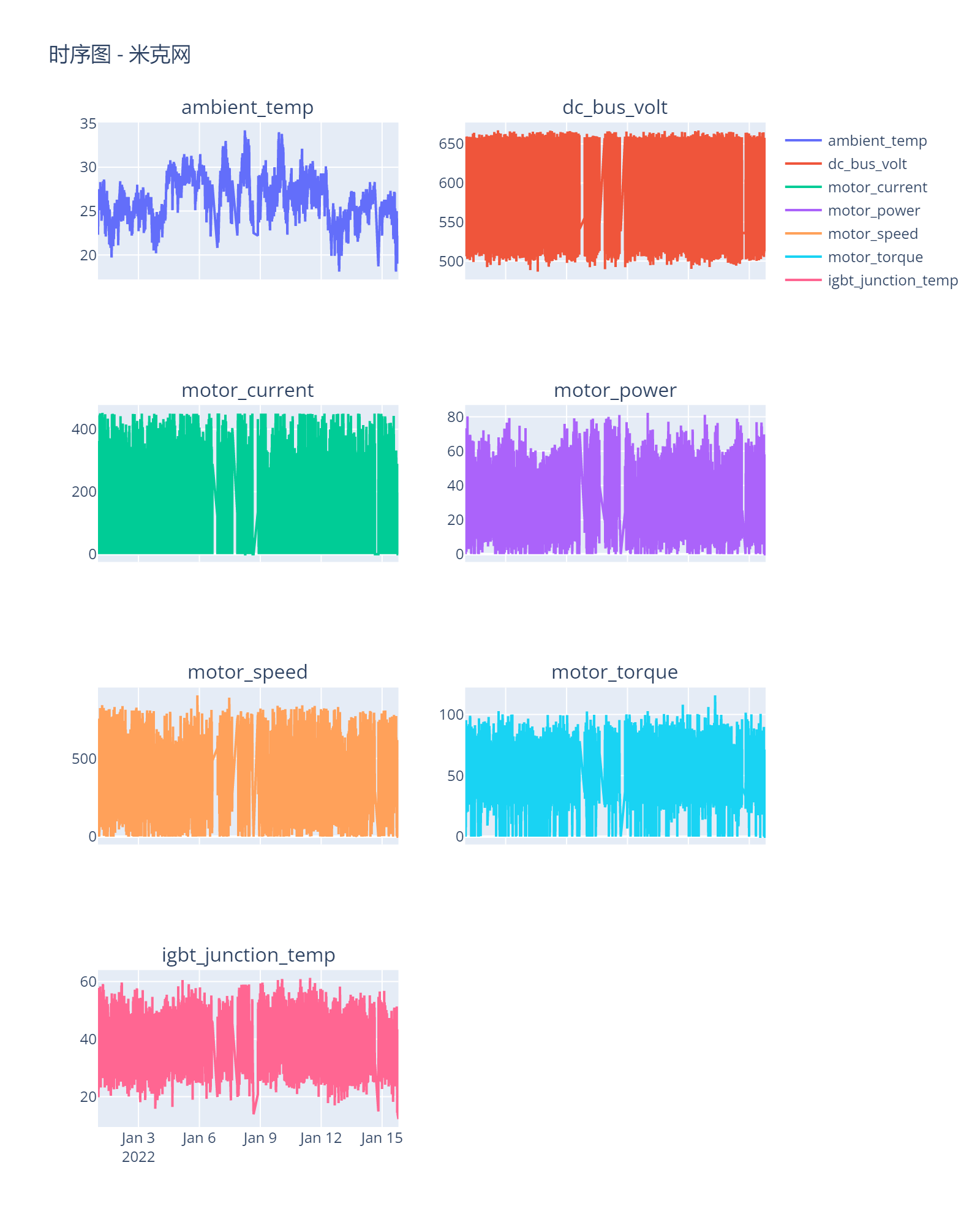
大概可以看到数据中有很多地方不是很连续。
从环境温度的波动情况看,这个测试似乎是在室外进行的,而不是实验室内进行的。这是否说明是在整车实况下测量到的数据。
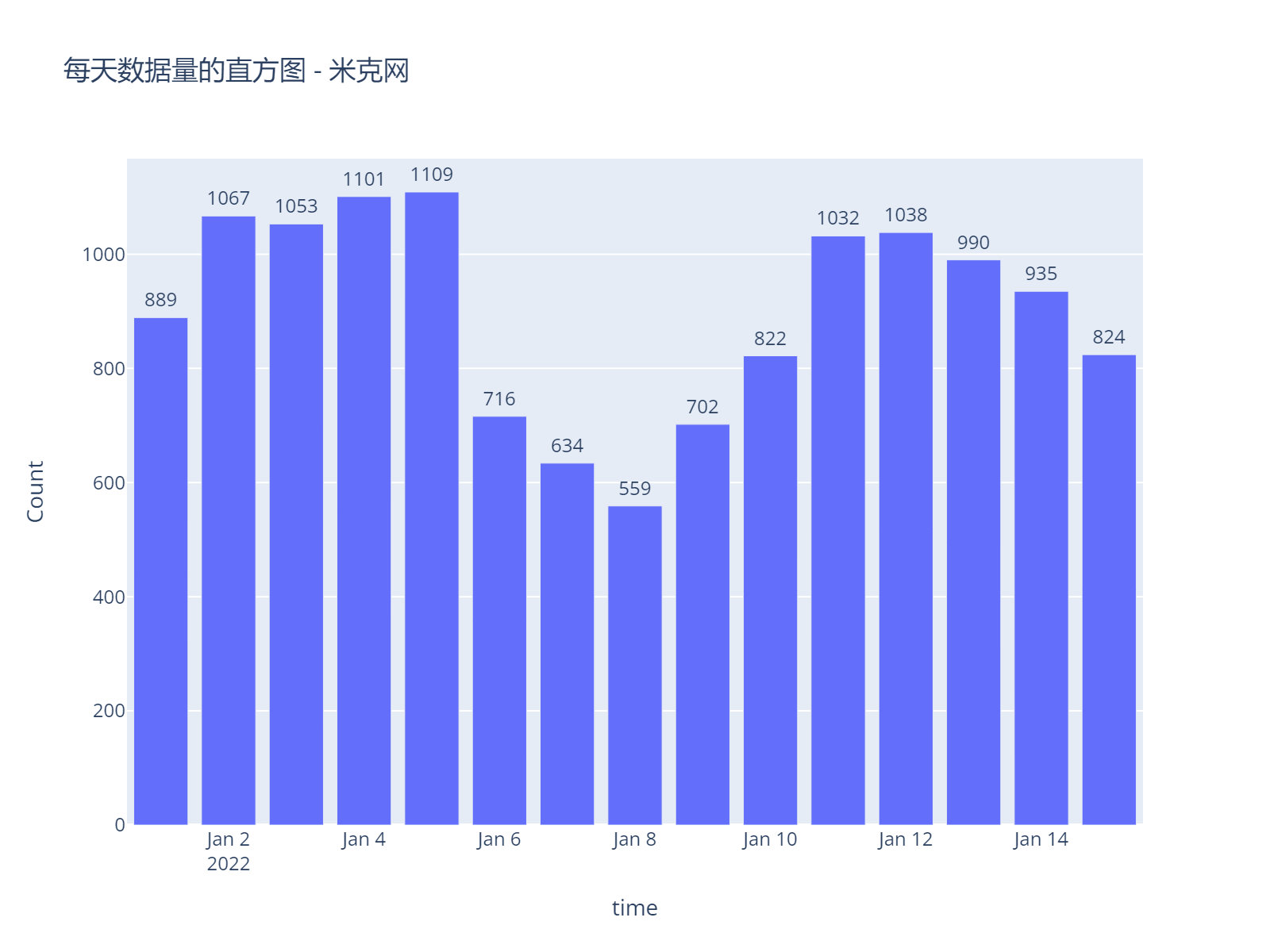
那么我们看看每天记录的数据情况,如下图,每天记录的数据数量不一定,大概在600~1100条之间。
可能是因为设备没有连续工作,或者每天测试记录的时间,记录数据量不一导致的。
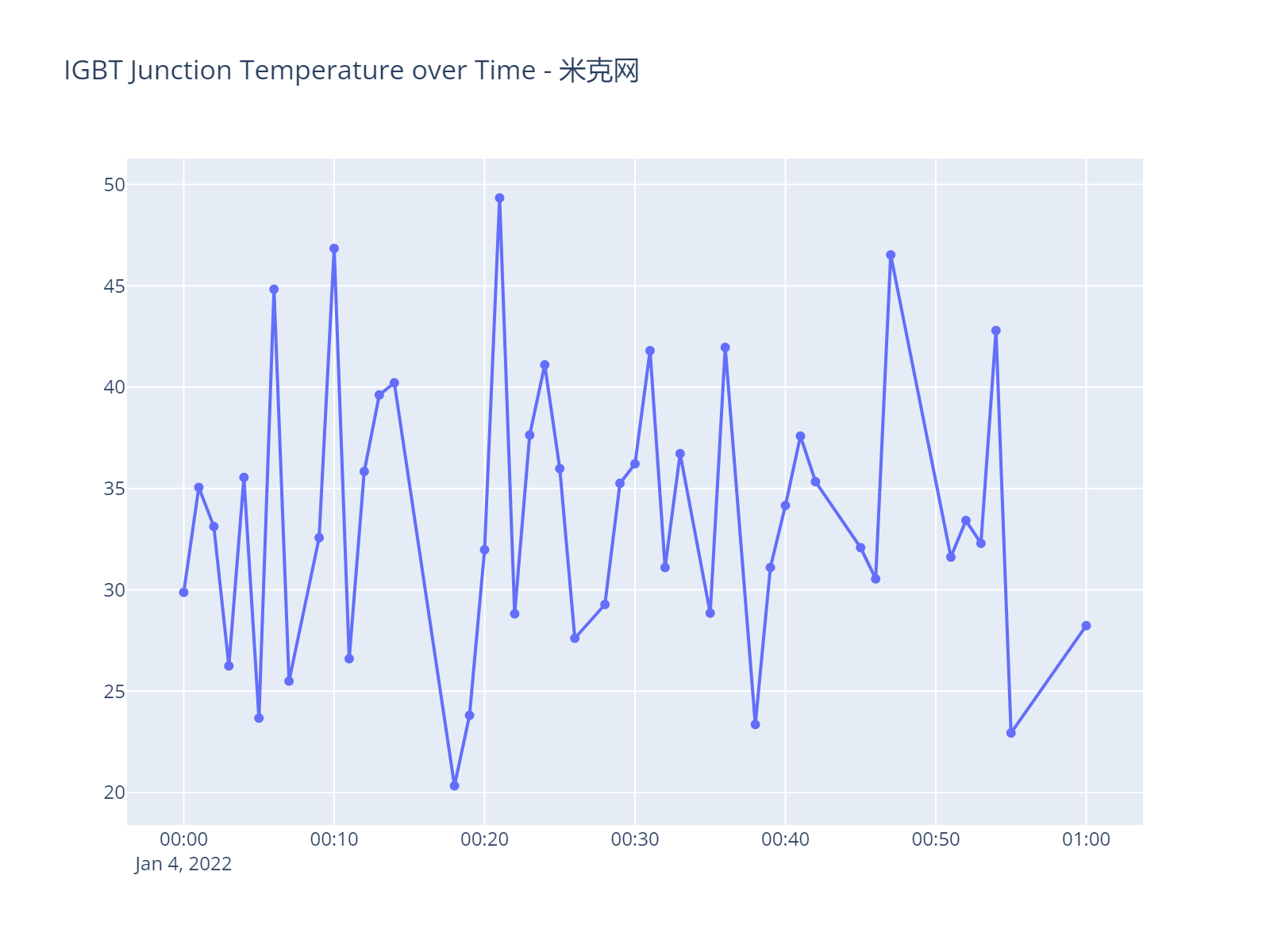
另外为了查看记录的特征与时间的关系,这里查看一段局部时间,查看1月4日一个小时的IGBT温度数据
import plotly.graph_objects as go
# 设置图片尺寸
fig_size = (800, 600)
# 折线图:时间与IGBT Junction Temperature的关系
# 选取df时间为2022-01-04 00:00:00到2022-01-04 00:10:00的数据
df_s = df[(df["time"] >= "2022-01-04 00:00:00") & (df["time"] <= "2022-01-04 01:00:00")]
fig1 = go.Figure()
fig1.add_trace(
go.Scatter(
x=df_s["time"],
y=df_s["igbt_junction_temp"],
mode="lines+markers",
name="IGBT Junction Temperature",
)
)
fig1.update_layout(
width=fig_size[0],
height=fig_size[1],
title="IGBT Junction Temperature over Time - 米克网",
)
# 显示图表
fig1.show()
如下图数据点密集的地方大概是1分钟采集一次,也不一定,有的时间间隔可能为2分钟。总之,在时间分布上不均匀。
另外,这个数据集的间隔这么大,不确定是否合适做预测,会不会存在温度和其他变量不匹配的问题,因为温度和其他变量会存在一些滞后性,不可能和电流在同一瞬间发生变化。如果是一段时间的平均值,也还好,但是我们没有这些说明信息。
数据分布
下面我们看一下各变量的分布情况
import plotly.express as px
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import numpy as np
from scipy.stats import gaussian_kde
# 创建子图
fig = make_subplots(rows=4, cols=2, subplot_titles=df.columns[1:])
# 添加直方图和KDE曲线到子图
for i, col in enumerate(df.columns[1:]):
row_num = i // 2 + 1
col_num = i % 2 + 1
# 绘制直方图
hist_trace = go.Histogram(x=df[col], nbinsx=50, name=f'{col}', opacity=0.75, histnorm='probability density')
fig.add_trace(hist_trace, row=row_num, col=col_num)
# 计算KDE曲线
kde = gaussian_kde(df[col].dropna())
x_vals = np.linspace(df[col].min(), df[col].max(), 100)
y_vals = kde(x_vals)
# 添加KDE曲线
kde_trace = go.Scatter(x=x_vals, y=y_vals, mode='lines', line=dict(color='red'), showlegend=False)
fig.add_trace(kde_trace, row=row_num, col=col_num)
# 更新布局
fig.update_layout(height=row_num * 300, width=800, title_text="直方图和KDE曲线 - 米克网")
# 显示图表
fig.show()
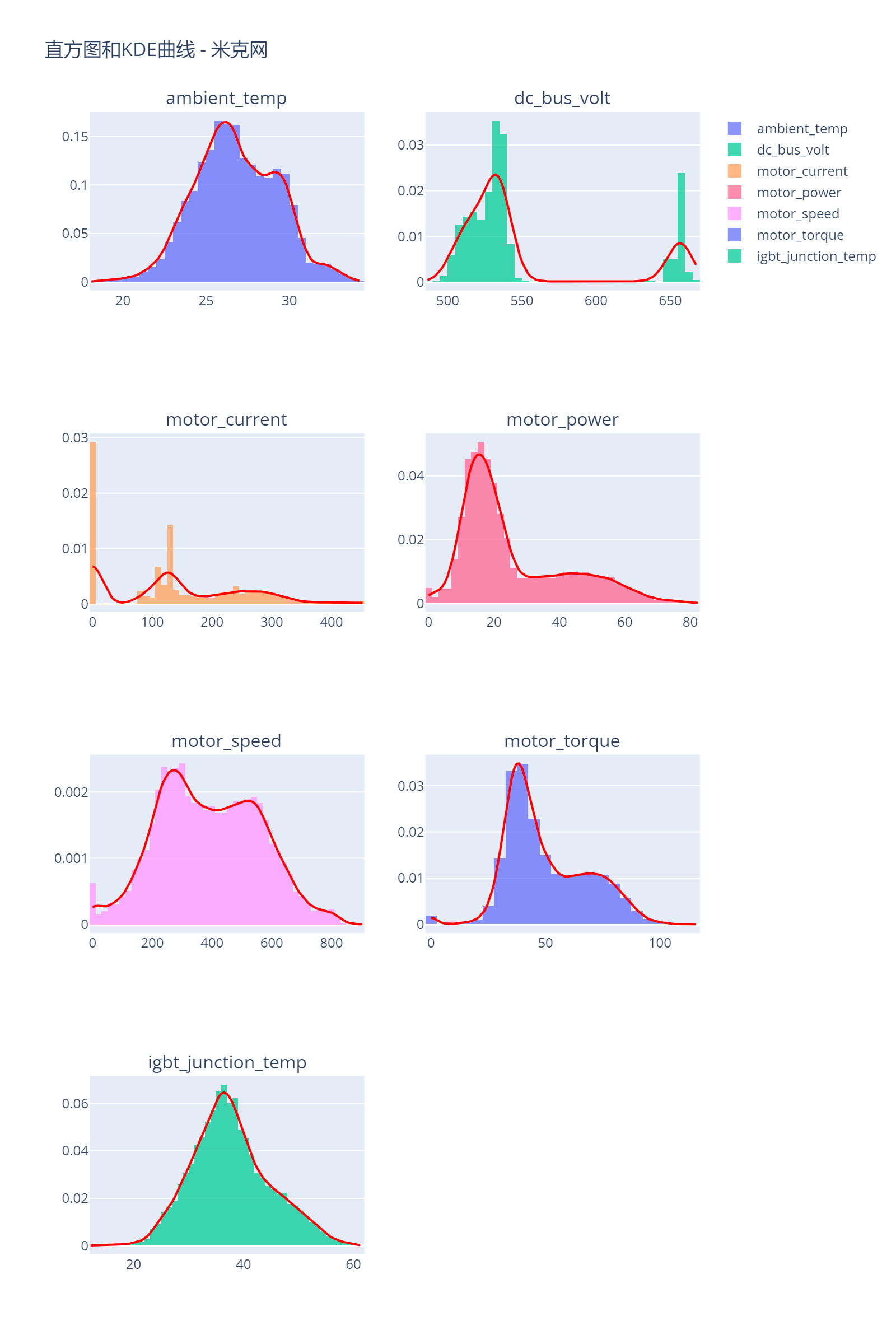
通过分布图,我们可以看出这些特征的分布情况。
- 环境温度和IGBT有一个峰值
- 电机电流(motor_current)出现较多的0值
- 电机功率(motor_power)和电机扭矩(motor_torque)的在高值部分出现较长的尾巴,可能包含一些较大的异常值。我们需要在预处理阶段处理这些异常值,以防止它们对模型的影响。(这部分异常值的处理参考LeeLeon_MS的说法,我不确定这是否是异常值)
接下来,绘制各变量的箱线图(Boxplot)进行可视化,箱线图可以清楚地看出数据的中位数、四分位数以及异常值。
import plotly.express as px
from plotly.subplots import make_subplots
import plotly.graph_objects as go
# 创建子图
fig = make_subplots(rows=4, cols=2, subplot_titles=df.columns[1:])
# 添加箱线图到子图
for i, col in enumerate(df.columns[1:]):
row_num = i // 2 + 1
col_num = i % 2 + 1
# 绘制箱线图
box_trace = px.box(df, y=col, title=f"{col}")
fig.add_trace(box_trace["data"][0], row=row_num, col=col_num)
# 更新布局
fig.update_layout(height=row_num * 300, width=800, title_text="箱线图 - 米克网")
# 显示图表
fig.show()
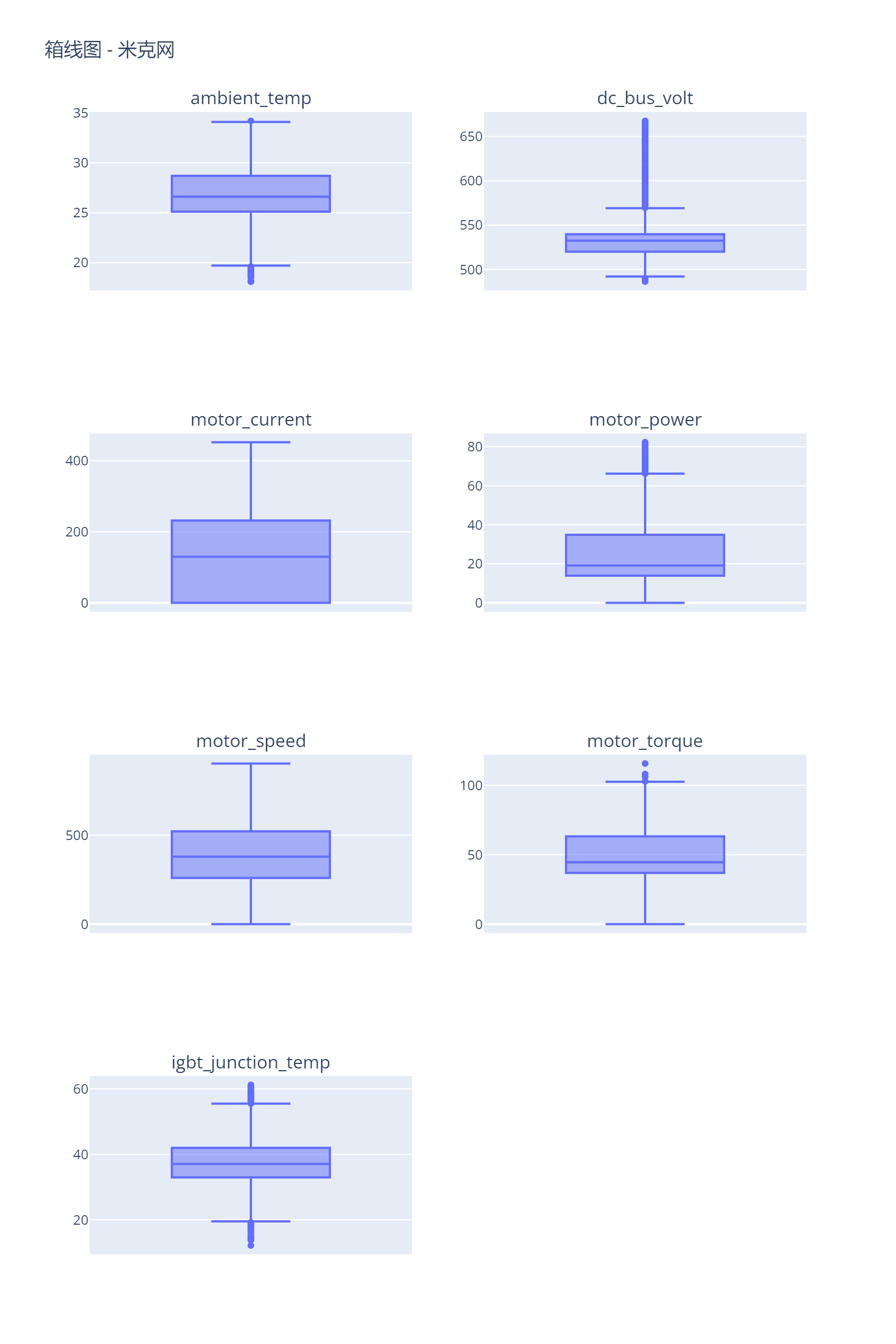
从箱线图中我们可以看出,大部分特征的分布都是相对集中的,但是“电机电流(motor_current)”,“电机功率(motor_power)”和“电机扭矩(motor_torque)”这三个特征存在一些较大的值,这些可能是异常值。
判断异常值的一种常用方法是使用四分位距(IQR)来定义正常值的范围。对于一个特征,我们首先计算其第一四分位数(Q1)和第三四分位数(Q3),然后计算四分位距IQR = Q3 - Q1。那么,小于Q1 - 1.5 IQR或大于Q3 + 1.5 IQR的值就被认为是异常值。
下一步,计算这三个特征的异常值,并决定如何处理它们。处理异常值的方式有很多种,例如可以直接删除这些异常值,或者将它们替换为某个值(例如平均值、中位数等),或者可以使用一些数据转换的方法(例如对数转换)来减小异常值的影响。
明天继续,异常值的处理部分,明天见。。。